Decision trees in rules-based AI applications
Decision trees represent a chain of questions that lead to an outcome. Each internal node asks a question (a rule), each branch shows what happens when that rule is true or false, and each leaf gives an action or classification. In rules-based AI, trees make human-authored logic explicit and auditable, which supports explainability and accountability in systems that must justify their decisions.
Syllabus alignment
This lesson supports the NSW Software Engineering Stage 6 syllabus:
-
Software automation / Algorithms in machine learning
- Research models used by software engineers to design and analyse ML, including decision trees.
In this section, you will first use decision trees as a rules-based technique: scientists develop the rules and programmers write the code for the AI that follows the rules and produces outcomes. Later, we will connect the same structure to machine learning (ML), where algorithms learn the rules from data rather than us hand-writing them.
In this section:
- Where decision trees fit into AI, focusing on rules-based systems (with links to ML for later modules)
- How decision trees work from root to leaf using your supplied graphics
- Uncertainty: reducing it, and handling missing, noisy or conflicting information in rules-based decision-making.
How decision trees work
Decision trees are a type of supervised machine learning model that focus on making predictions by asking a series of simple questions. They deal with one topic at a time and are most effective when trained with reliable data drawn from real examples.
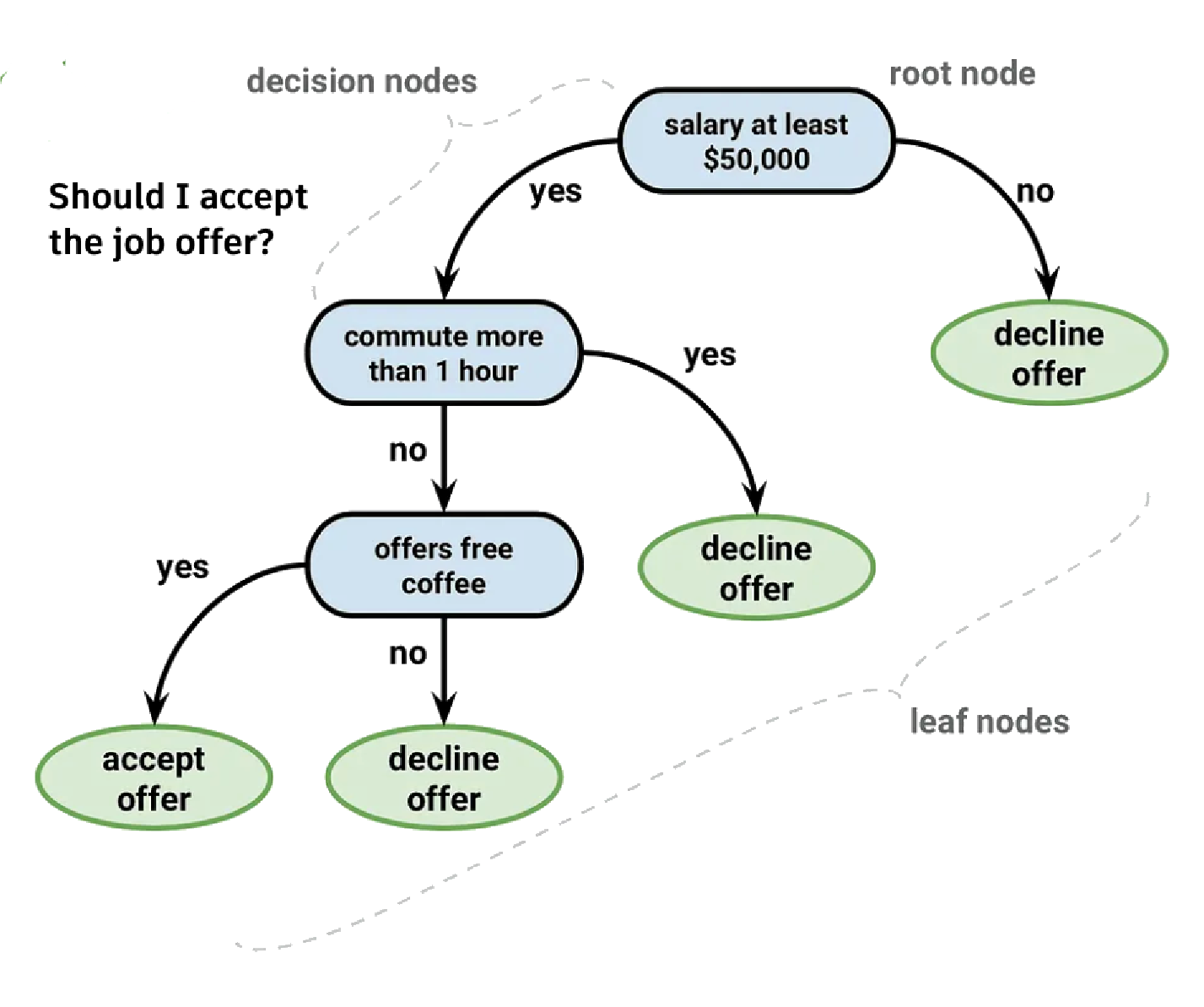
A decision tree is a tool that helps machines and people make choices step by step. It works by starting at a root question, such as 'Should I accept the job offer?', and following branches based on the answers until an outcome is reached, like 'accept offer' or 'decline offer'.
Decision trees are popular because they are easy to read, transparent in their logic, and suitable for many types of problems. This introduction will outline what decision trees are, how they work, and why they matter in automation.
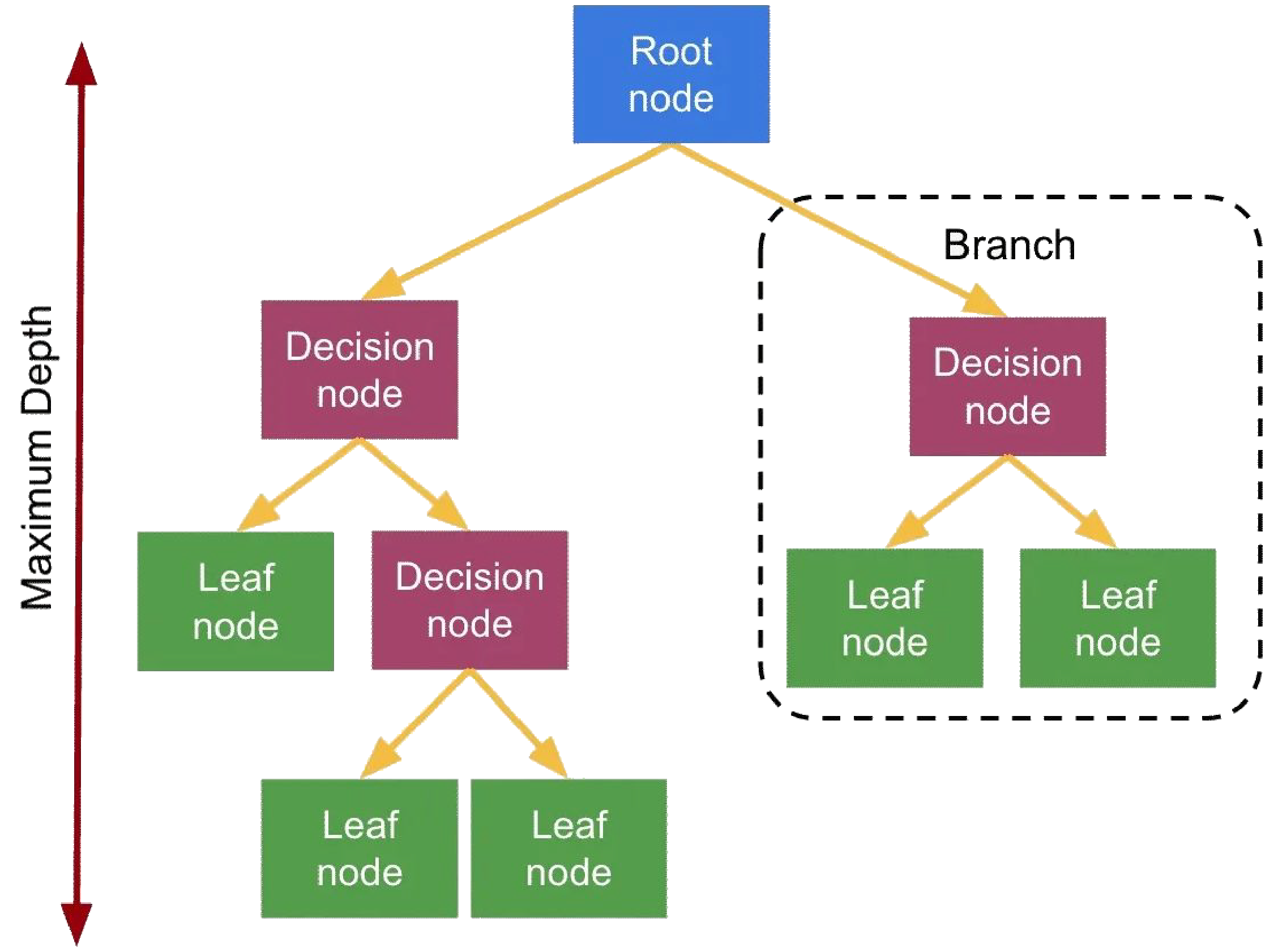
Decision tree anatomy
Decision trees demonstrate branching logic, like that used in code for IF/ELIF/ELSE.
- The root node is the starting point of the tree where the first question is asked.
- A decision node is a point in the tree where the data is split based on a condition.
- A branch is the path that connects nodes, representing the outcome of a decision.
- A leaf node is the end of a branch where the final prediction or outcome is given.
Why use decision trees
Real-world datasets are rarely simple enough to separate with a single line. Decision trees overcome this by splitting data step by step, making them powerful tools for dealing with complex, non-linear patterns that occur in everyday problems.
By asking a series of questions, a decision tree divides the data in a way that allows us to separate non-linear datasets (Figure 2). The process follows a path through the tree, effectively handling more complex data distributions, as shown in the image below.
In many real-world scenarios, data is not perfectly linearly separable. Consider the dataset shown (Figure 1), where two classes are separated by a single line. This is called a linearly separable dataset. However, in actual datasets, it’s rare for data to be perfectly linearly separable. Often, a single line cannot separate the classes effectively. This is where decision trees come in.
FIG. 1
This dataset is a linearly separable dataset because the two classes can be effectively divided by a single straight line.
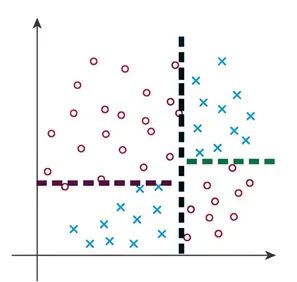
FIG. 2
The two classes in this dataset cannot be separated by a single straight line. Instead, they are segmented into sections, which is what the corresponding decision tree would represent.
How decision trees work
Top down decision making
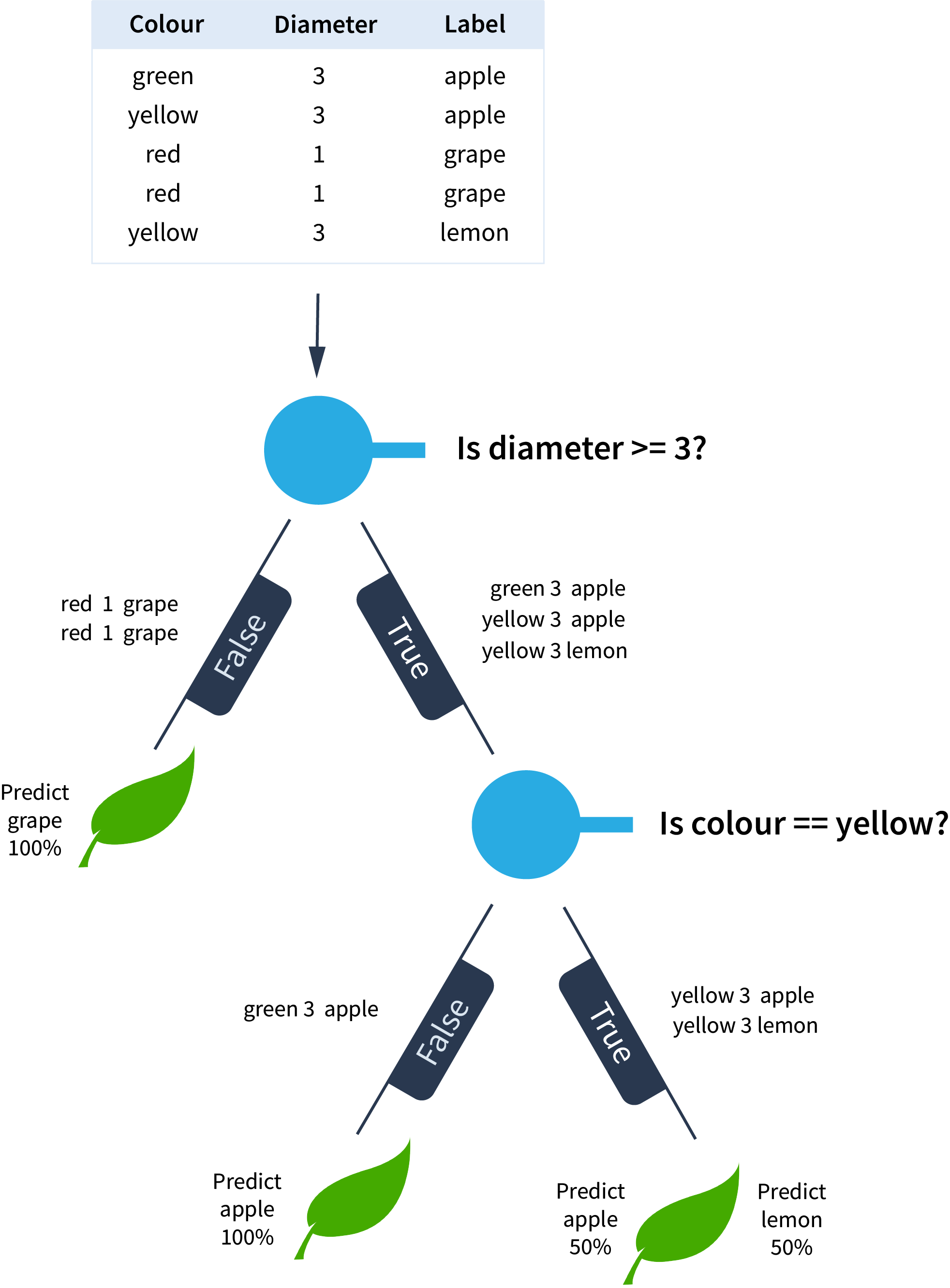
- Dataset
We start with a dataset on the characteristics of fruit in order to classify them. - Root node
We ask the first question about the fruit's diameter. - Root node
The true condition returns three different data points and will require another node for further classification. The false condition returns two identical data points with diameter < 3 and both are grapes. Based on this dataset, the decision tree predicts grapes with 100% accuracy. - Level 1 node
We ask a question about the fruit's colour. The true condition gives two data points with colour == yellow, one being a lemon and the other being an apple. The decision tree predicts lemons with 50% accuracy and yellow apples with 50% accuracy. The false condition gives one data point with colour != yellow, a green apple. The decision tree predicts green apples with 100% accuracy.
Information gain
How decision trees choose the best split
Decision trees separate data by asking questions, but not all questions are equally useful. To decide where to split, they measure uncertainty and aim to minimise it. This reduction is called information gain.
When a dataset is mixed, it has high impurity or uncertainty. For example, if apples, grapes, and lemons are all in the same group, the algorithm is unsure which label to predict. By asking a question like ‘Is the colour green?’, the tree splits the data into two groups. One group may become pure (all apples), while the other remains mixed. The difference in impurity before and after the split is the information gain.
A higher information gain means the question is more effective at separating the data. Decision trees select the split with the highest information gain, continuing this process until the data is well organised into clear categories.
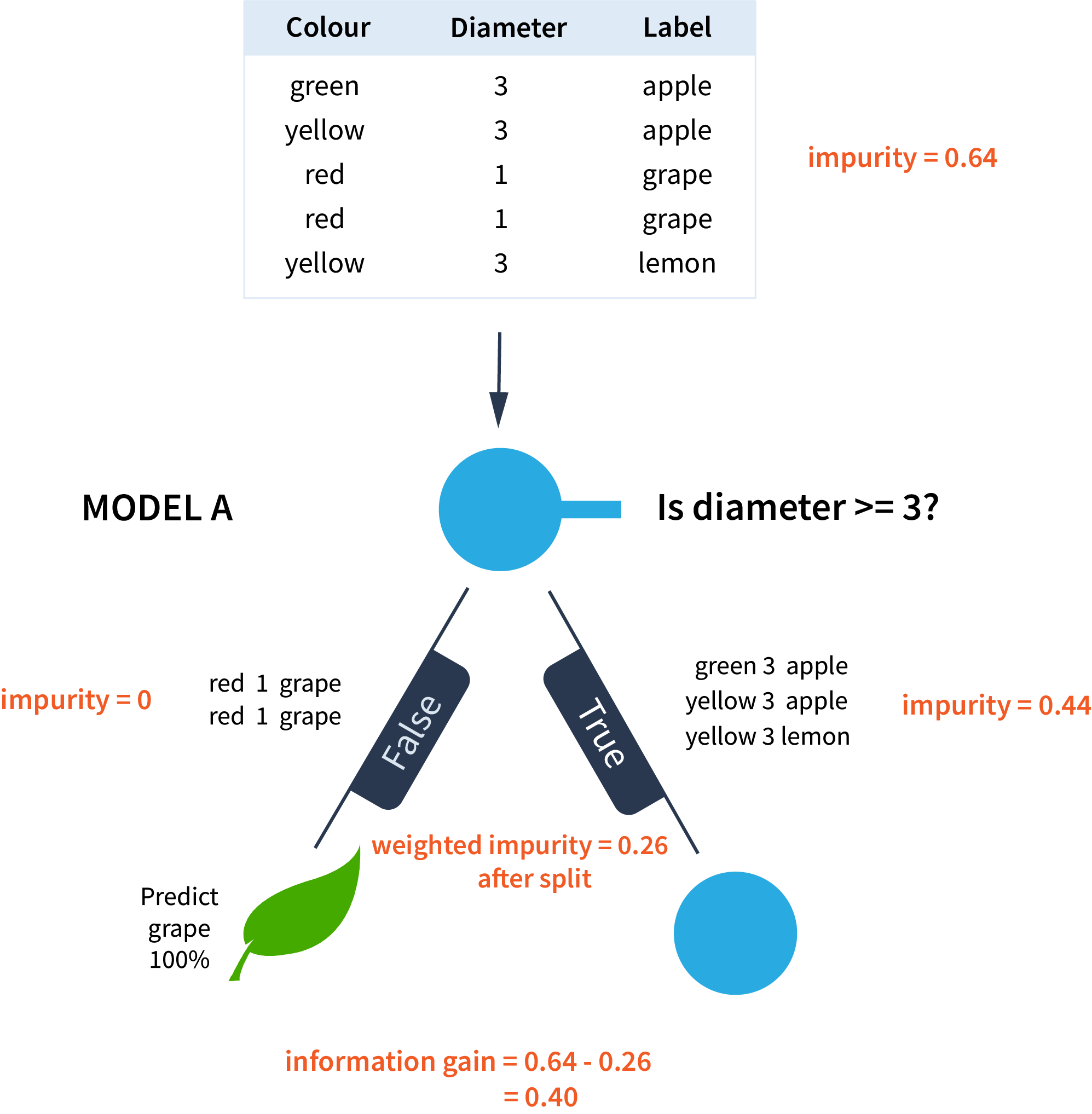
MODEL A
Is the diameter >= 3?
In this model, the question asked is whether the diameter of the fruit is greater than or equal to 3. The sorting that results reduces the impurity of the dataset from 0.64 to 0.26 after the split.
The disorder in the dataset is reduced from an initial impurity of 0.64 to a weighted impurity of 0.26 after the first split. This results in an information gain of 0.40.
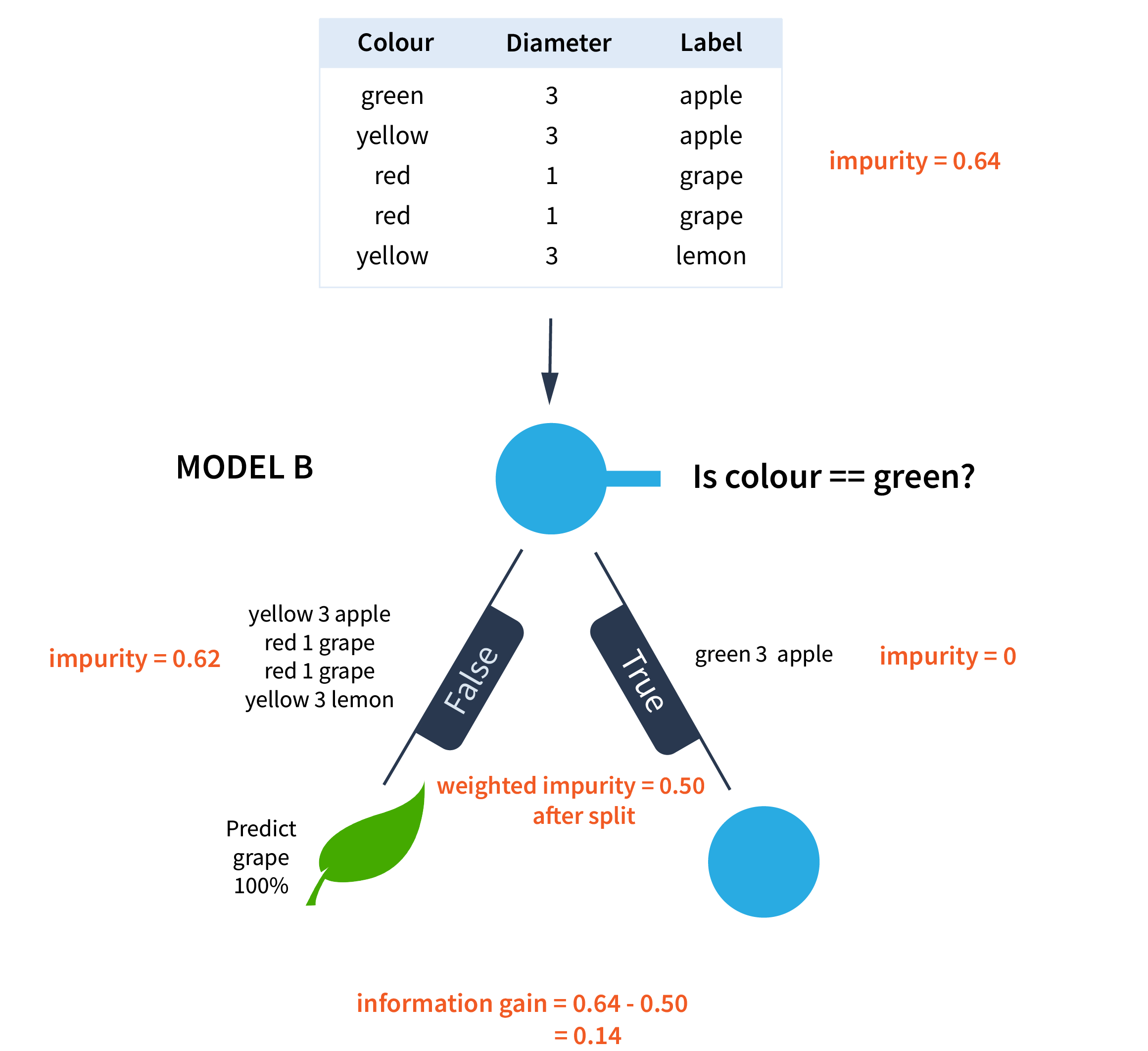
MODEL B
Is the colour == green?
In this model, the question asked is whether the colour of the fruit is green. The sorting that results reduces the impurity of the dataset from 0.64 to 0.50 after the split.
The disorder in the dataset is reduced from an initial impurity of 0.64 to a weighted impurity of 0.50 after the first split.
This results in an information gain of 0.14.
The disorder in the dataset is reduced from an initial impurity of 0.64 to a weighted impurity of 0.26 after the first split.
This results in an information gain of 0.40.
Those questions with larger informqation gains are better questions in a decision tree.
Key terms
- Decision tree
A model that predicts by asking a sequence of questions, following branches to a final outcome. - Root node
The first question in the tree where the initial split happens. - Decision node
Any internal node that splits data based on a condition (e.g., colour == green). - Leaf node
An endpoint that outputs the final prediction or action. - Branch
The path between nodes representing the result of a question. - Depth
The number of levels from the root to the deepest leaf; deeper trees can overfit. - Feature
An input variable used to make a split (e.g., diameter, colour). - Target (label)
The value the model is trying to predict (e.g., fruit type). - Impurity
A measure of how mixed a node is; common metrics are Gini and entropy. - Gini impurity
Split metric used by CART; lower values mean purer nodes. - Entropy
Information theory measure of uncertainty used in ID3/C4.5. - Information gain
The reduction in impurity from a split; trees choose the split with the highest gain. - Overfitting
When the tree memorises noise in training data and performs poorly on new data. - Pruning
Techniques that shrink or stop growth of a tree to reduce overfitting. - Classification tree
Predicts categories (e.g., apple vs grape); often uses Gini or entropy. - Regression tree
Predicts continuous values (e.g., price); uses variance reduction. - Train/test split
Separating data to evaluate generalisation on unseen examples.